Industrial Data & AI Solutions Builder
As an engineer focused on industrial data, my role is to analyze operational data and connect it to better decision-making. I focus especially on regulated and mission-critical industrial domains, designing and implementing scalable data pipelines, predictive maintenance models, and dashboards powered by AI.
This approach optimizes the flow of data and accelerates decision-making, helping organizations improve operational efficiency while maintaining competitiveness. Through technical innovation, it contributes to productivity, risk management, and sustainable growth.
About Me
Turning Industrial Data
into Operational Intelligence
Working where data, AI, and product reliability meet, I build and operate predictive maintenance, quality analytics, and design-verification workflows for globally deployed precision instruments in a regulated industry.
At Hitachi High-Technologies, I contribute to fleet-scale AI predictive maintenance development with international R&D partners, drive root-cause analytics on operational telemetry, and act as the bridge between equipment domain knowledge and the data-science teams that turn it into models.
I'm passionate about bridging the OT / IT gap in regulated, mission-critical industries, and I thrive in environments where data engineering and hands-on domain expertise combine to drive real-world reliability and cost outcomes.
What I Bring
Domain Expertise
Hands-on understanding of operational data from globally deployed precision instruments — failure modes, sensor characteristics, and end-user maintenance workflows.
Full-Stack Data Engineering
From raw sensor ingestion (REST/Kafka) to data modeling, cleansing, transformation, and visualization — I own the full pipeline.
AI-Augmented Solutions
Building ML models and AI agents that translate data patterns into actionable maintenance decisions, not just dashboards.
Cloud & DevOps Mindset
CI/CD-first development with Docker, GitHub Actions, and Azure — building solutions that scale beyond the initial pilot.
Technical Skills
Stack & Tooling
Languages
Data & ML
Cloud & Infrastructure
Data Visualization
Integration & APIs
DevOps & Quality
Experience
Career Timeline
Building industrial intelligence through data engineering and predictive analytics.
- Contributed to fleet-scale AI predictive maintenance development for globally deployed precision instruments, partnering with an international R&D collaborator on data-sharing governance, schema definition, and feature design — translating equipment domain knowledge into ML inputs and supporting product-grade deployment of the resulting models.
- Owned operational telemetry analytics on a globally deployed product fleet, combining statistical analysis (FTA, fishbone, multivariate inspection of ~50 quality channels) with on-site root-cause investigation; drove an order-of-magnitude reduction in out-of-spec rate on a key process metric.
- Co-developed an automation robotics initiative for clinical-workflow tasks: facilitated cross-functional design reviews, designed and analysed a quantitative product-evaluation survey, and was named co-inventor on a filed patent on human–robot collaboration.
- Led design verification across multiple parallel themes in coordination with international R&D peers in Europe, running technical reviews in English; contributed data, calculation tooling, and regulatory documentation to a manufacturing-transfer programme that launched ahead of schedule.
- Continuously deepen ML / AI skills outside core work — Kaggle competitions, completion of a graduate-school medical-AI programme, G-Test (JDLA Generalist) certification, and active engagement with academic conferences on medical AI and computer vision.
Featured Project
Predictive Maintenance on NASA CMAPSS
Open-source implementation
predictive-maintenance-cmapss
An end-to-end Python pipeline on NASA's CMAPSS turbofan degradation dataset — strict-schema data loader, feature engineering, baseline and gradient-boosted RUL regressors, with executed Jupyter notebooks showing every result.
Results from the executed notebooks
Benchmarks using FD001
Every figure below is rendered straight from the executed notebook in the repository — click any card to open the full notebook on GitHub.
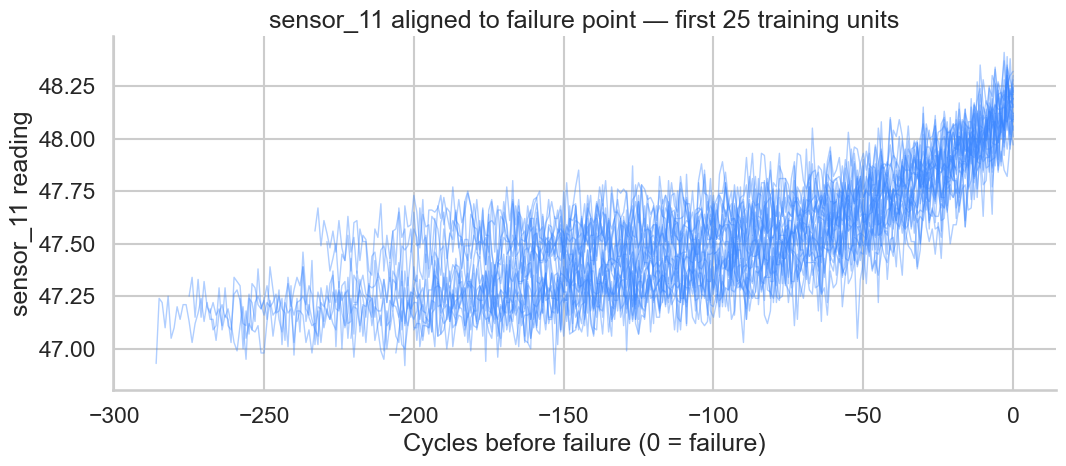
EDA — trajectories aligned to failure
25 training units, sensor 11 plotted vs. cycles before failure. Clean monotonic drift in the last ~80 cycles motivates the piecewise-linear RUL relabelling.
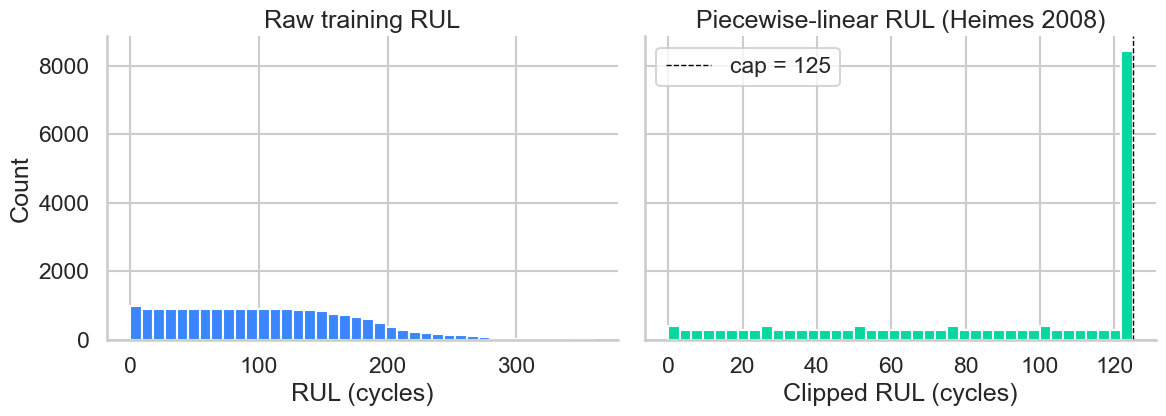
RUL distribution — raw vs. clipped
Capping the regression target at 125 cycles concentrates model capacity on the regime where degradation is observable. Heimes (2008) convention.
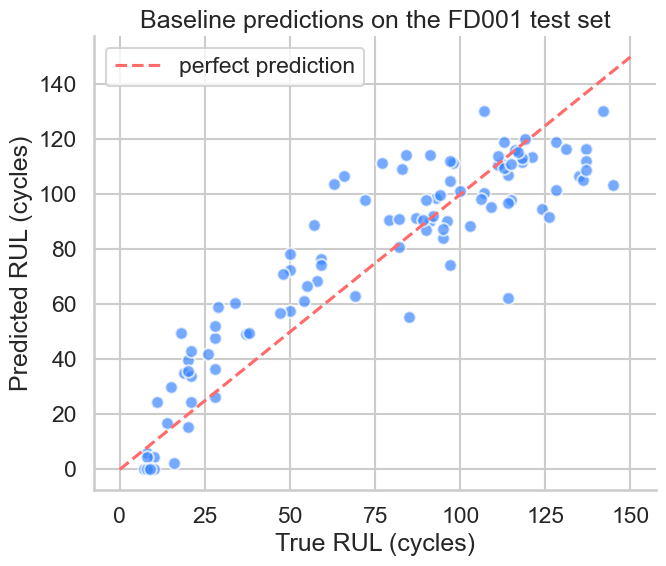
Ridge baseline — RMSE 18.27 / S-score 592.6
Standard-scaled L2 regression on rolling features. Sets the floor that any non-linear model must clearly beat to justify its complexity.
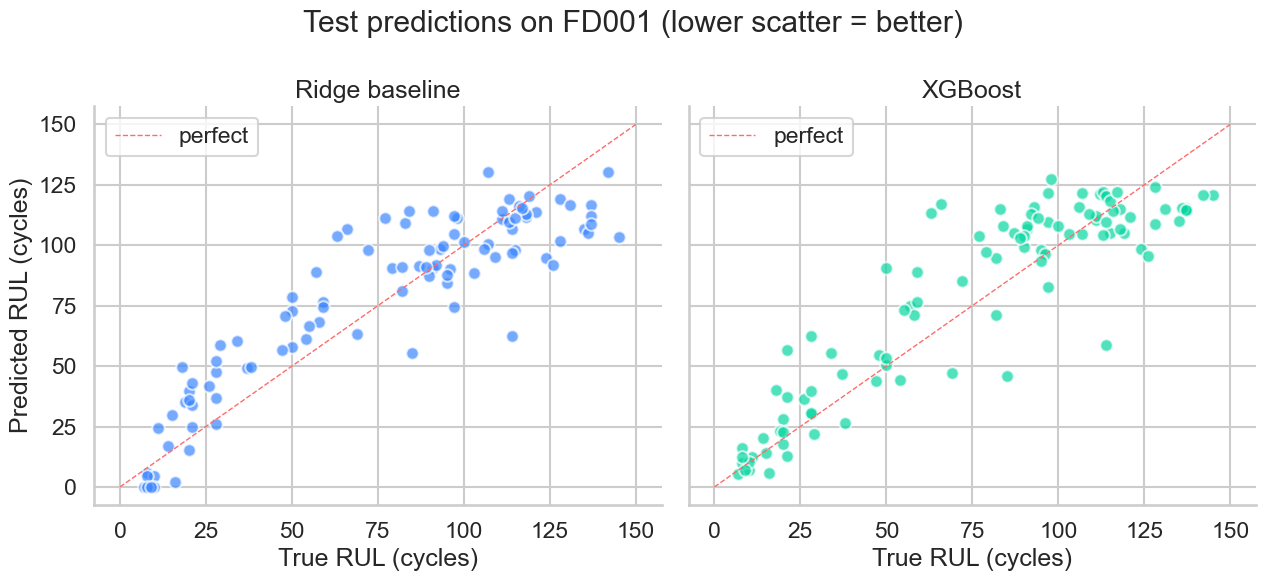
XGBoost head-to-head — RMSE 18.23 / S-score 814.8
Tuned XGBoost edges out Ridge on RMSE but loses on the asymmetric S-score. The honest result: FD001's single regime is exactly where linear features compete with trees.
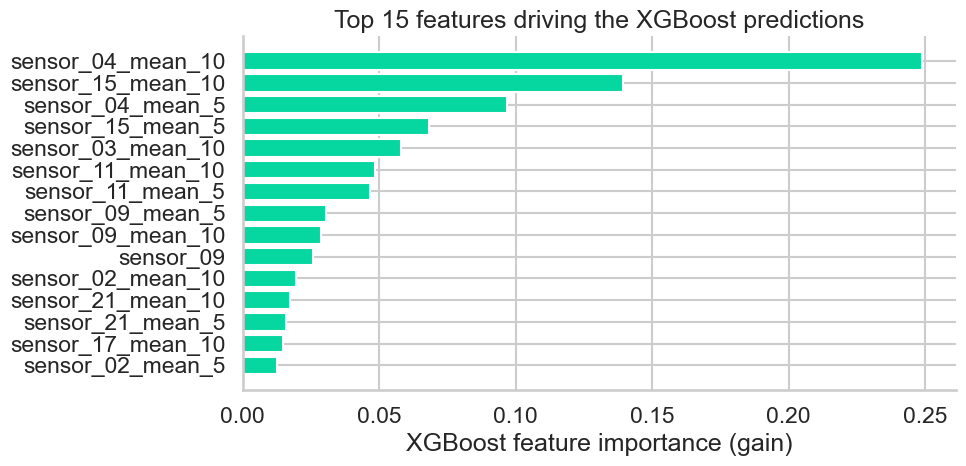
Feature importance corroborates the EDA
Rolling statistics on high-pressure-compressor sensors dominate — exactly the channels whose drift was visible in the EDA notebook.
Coming next
FD002 / FD004 multi-regime evaluation
Operating-regime clustering, regime-aware normalisation, and an LSTM sequence model over full trajectories — the setting where XGBoost is expected to clearly win.
Track progress on GitHub →Interactive concept preview
Synthetic dashboard — live in your browser
A self-contained Plotly visualisation of what the same pipeline looks like running against real-time sensor streams. The data is synthetic so the page stays static — for the actual benchmark numbers, see the cards above.
Multi-Sensor Time Series — Degradation Monitoring
RUL Prediction — Actual vs. Predicted
Anomaly Detection — Operating State Classification
Equipment Health Score (Current)
Concept summary
| Sensors | Vibration, Temperature, Pressure |
| Cycles | 300 operating cycles |
| Alert threshold | Health score < 30% |
| Implementation | eastani/predictive-maintenance-cmapss ↗ |
Architecture
Data Pipeline Design
Example E2E data flow
Contact